About Chinese propaganda on Twitter: drawing data 📊
Some days ago the journalist Charlotte Godart contacted me and asked me to explain how to use my script tweet_analysis.py. Her goal was to convert Twitter datasets about Chinese propaganda into graphs, so that people can see how the Chinese government operates on Twitter to influence their opinion. While helping her I had the possibility to take a look at these datasets and they are intriguing, very different from the Internet Research Agency dataset. My unconfirmed theory is that the Chinese government bought some bots and fake accounts from third-party companies. China has a strong power on national internet services such as TikTok or WeChat (e.g. filters, censorship), not so much on external services, though, for now. I think this situation will change quickly.
A Global View
I merged the three datasets shared by Twitter in order to have a global view of the accounts’ activity. So, in the three datasets there are over 13 milion tweets and over 5.000 accounts, but the accounts suspended by Twitter are many more. I used the command:
python3 tweets_analysis.py --dirpath alldata -w -top -csv -txt -v
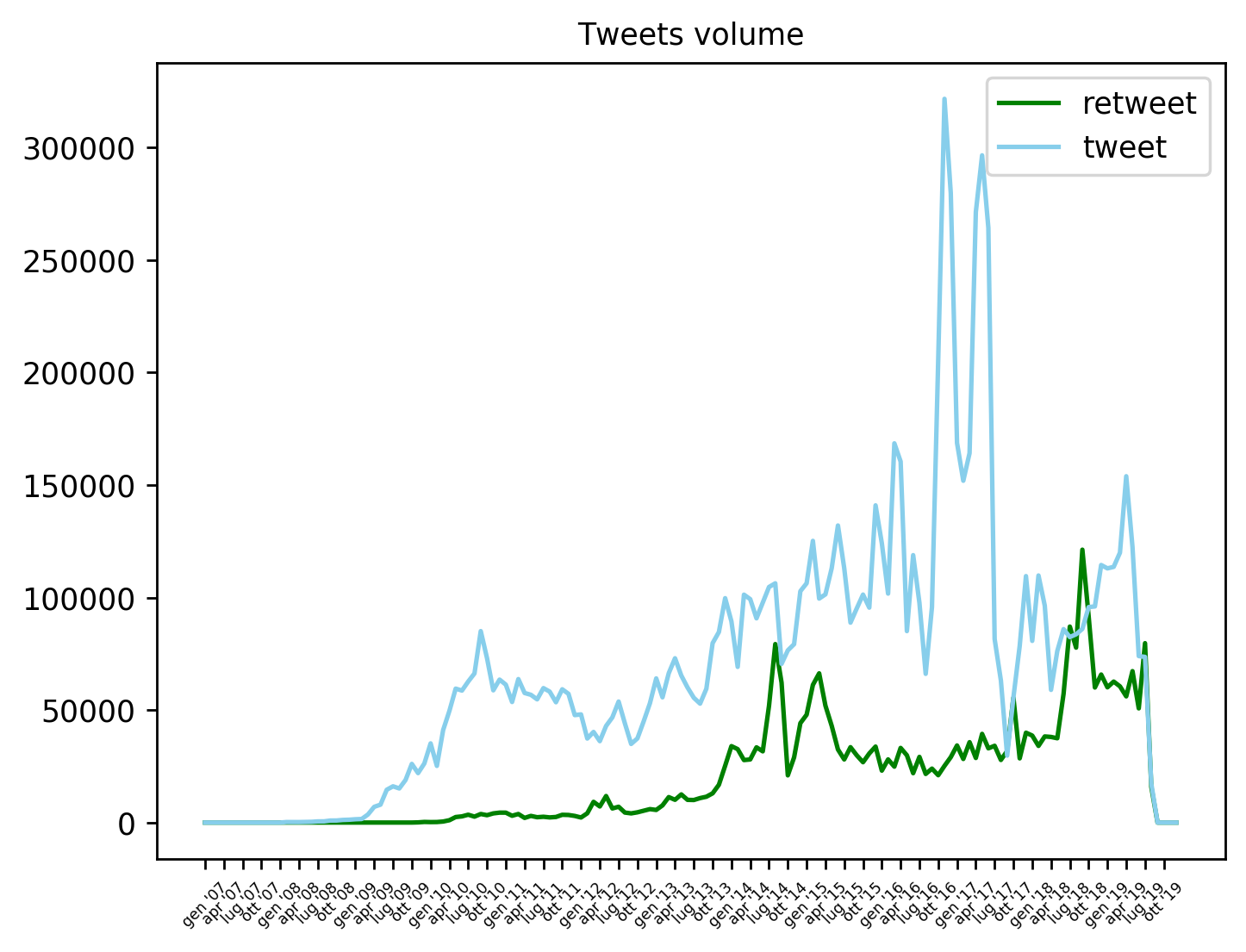
The most intensive activity took place during the first and last quarter of 2016, the second quarter of 2017 and the first semester of 2019. To better understand these datasets it is important to notice that not all these accounts were used to spread pro-China propaganda, many of them were only spam bots. The reason why Twitter has suspended them all is - in my opinion - that the people behind these networks, both spam bots and pro-China accounts, are the same. The graph also shows that these accounts generated more tweets than retweets.
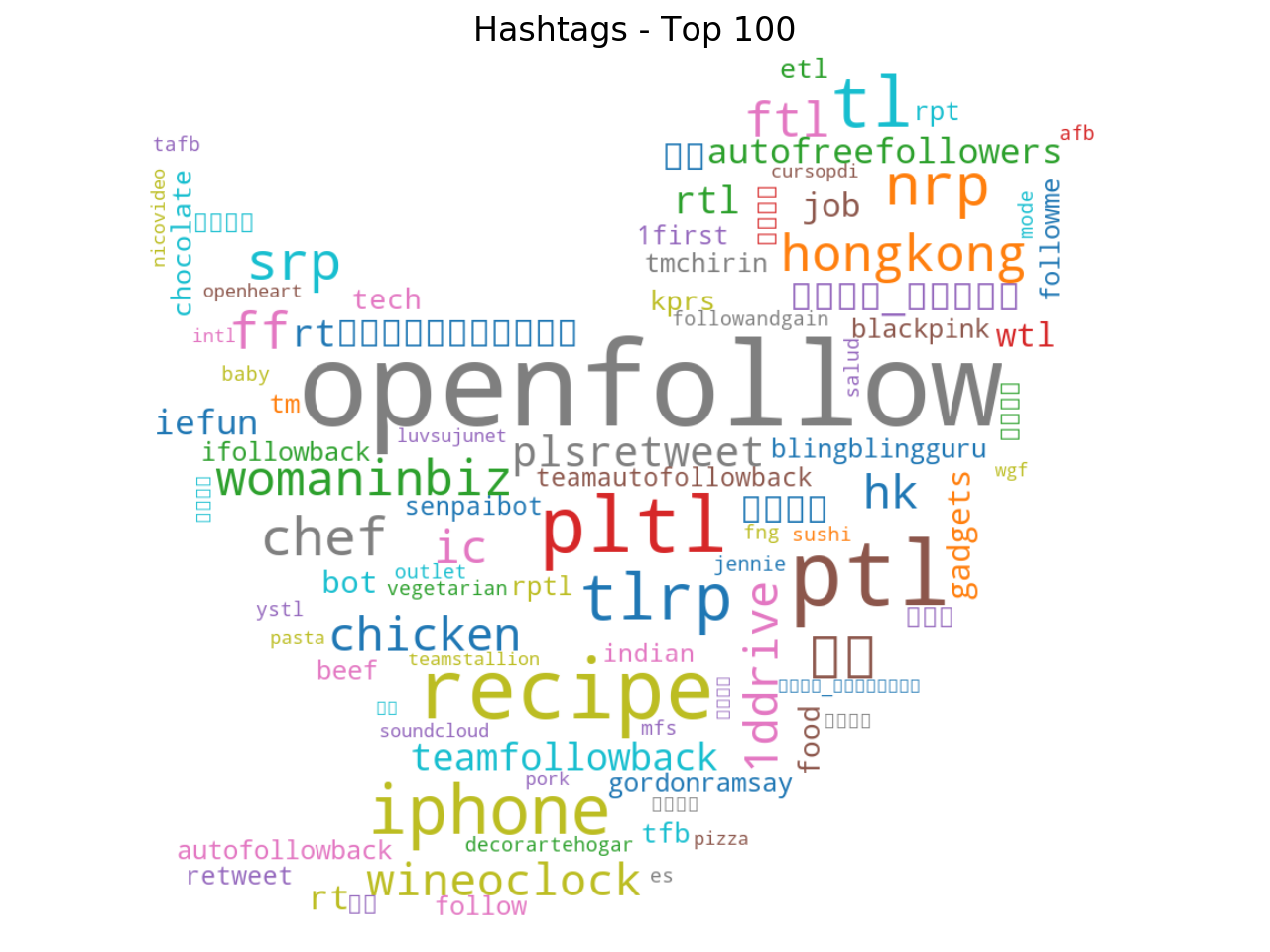
This wordcloud graph shows the 100 most frequent hashtags and it gives an idea of the hottest topics. The wordcloud confirms that many suspended accounts are part of a spam network: the hashtags #OpenFollow, #AutoFreeFollowers, #FollowMe or #TeamFollowBack are used to get more followers and they are the most frequent. The hashtag #HongKong is also very popular, it was used in 31.677 tweets. Below I will explain why, because it is very interesting.
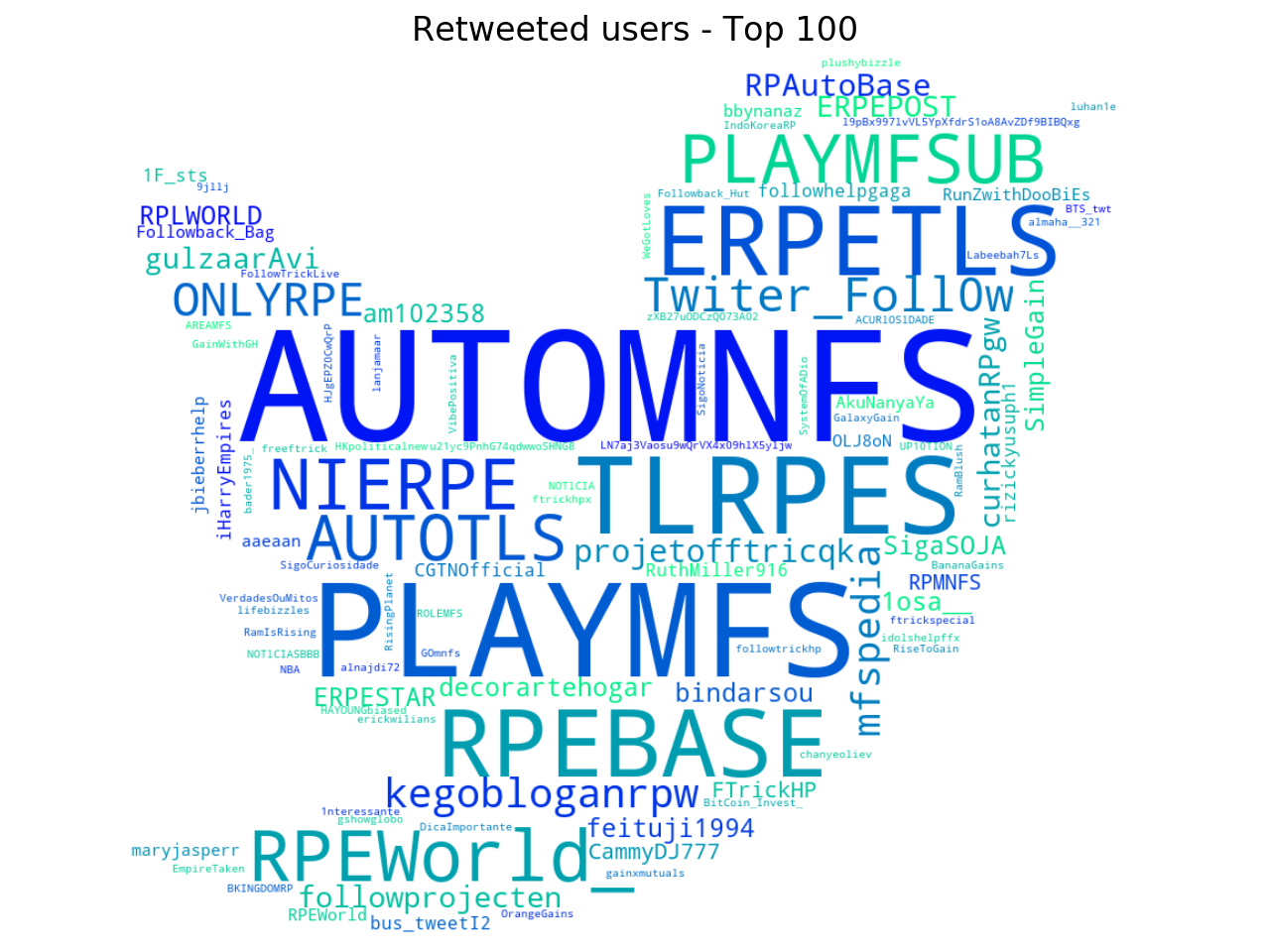
The wordcloud of the most retweeted users seems to confirm the previous one: many accounts are bots used to amplify tweets, and some of them were suspended by Twitter. Often Twitter suspends accounts that are retweeted by bots, although they aren’t in the dataset. There are other two important graphs about this giant dataset shared by Twitter: the barplots of the most used languages and the most used clients.
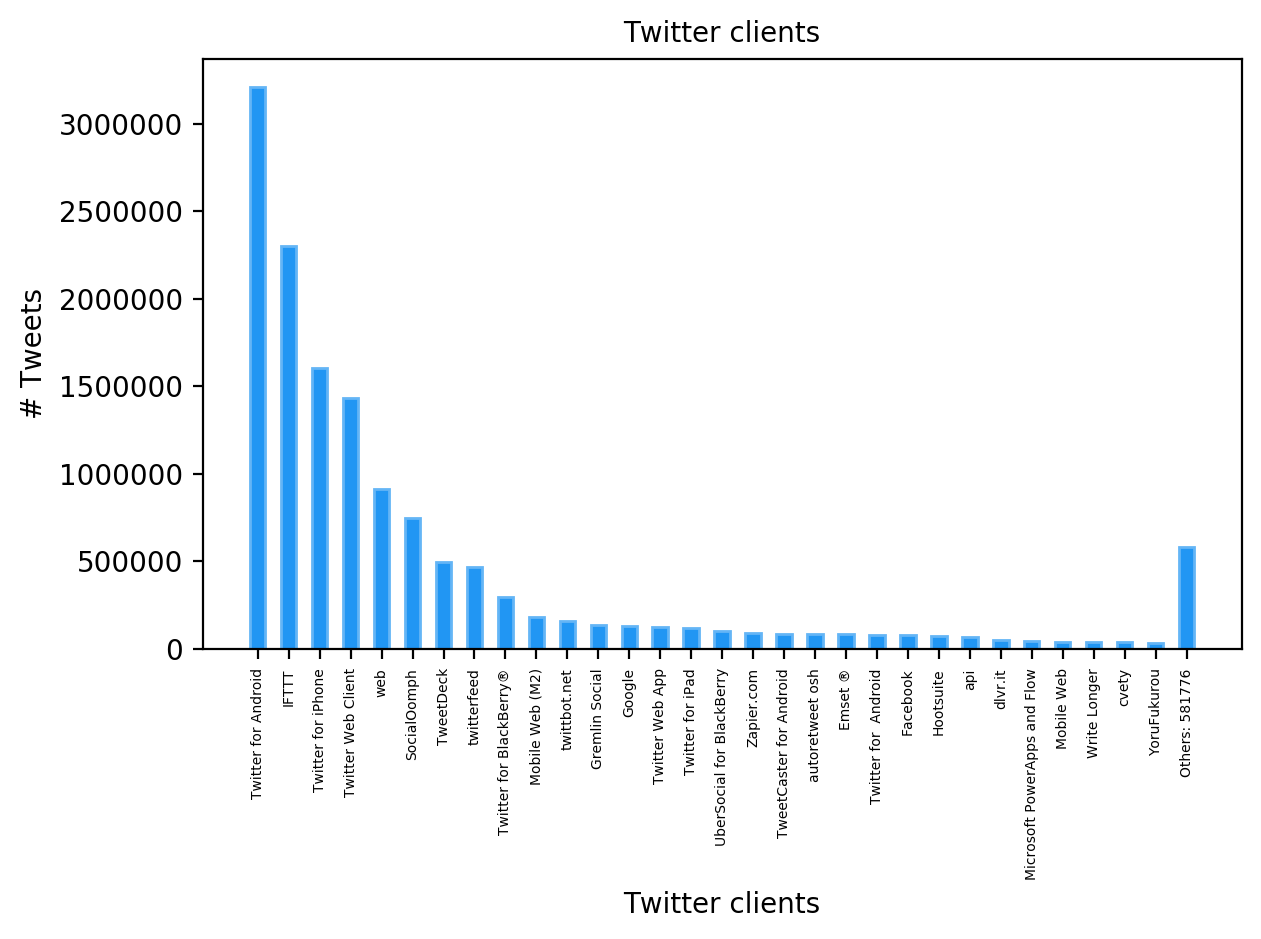
In the dataset there are many tweets posted on Android or iPhone, which is difficult to explain. However, if these accouts are part of a sophisticated spam-bots network, it is possible that a large number of people worked behind these accounts. Then, a single person could manage multiple accounts on different phones. It is nothing new, bots factories are a thing. Another hypothesis is that many accounts were created to be sold: the company created the accounts, increased their followers, then sold them. However, the clients information can be easily abused to deceive others (just remembering #FreeDorothy story).
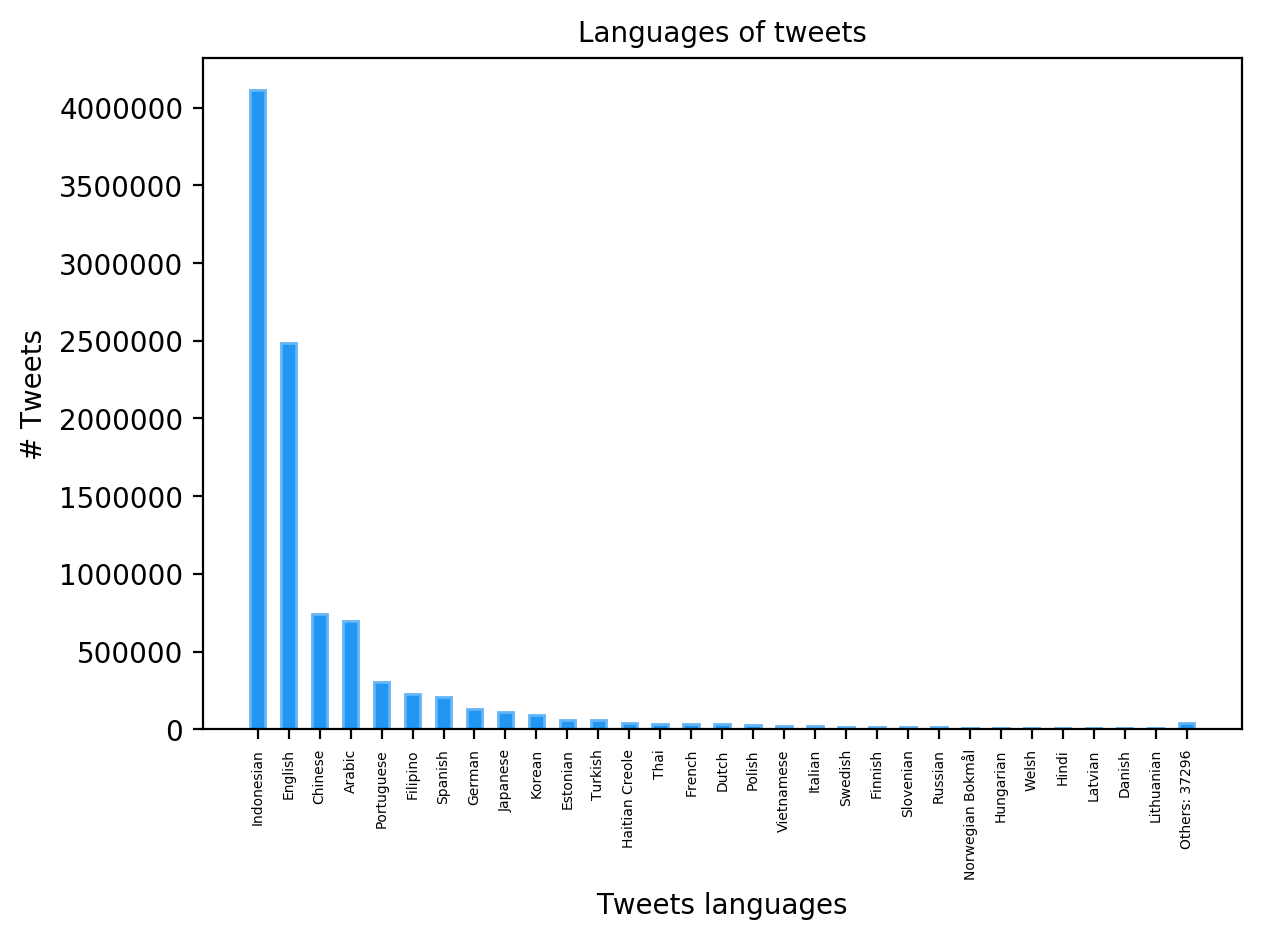
In this graph - the barplot of the most frequent languages - we can see that most of the tweets are written in Indonesian, if data are correct, then come English, Chinese and Arabic. A hypothesis for this fact is that this network - or networks - was targeting the Indonesian market and, perhaps, also the agency -the agencies - behind these accounts are Indonesian. My guess is that there are some Indonesian agents behind Chinese propaganda on Hong Kong protests, which is why Twitter wrote “state-backed information operation”. The last graph about the three datasets shared by Twitter regards the volume of interactions.
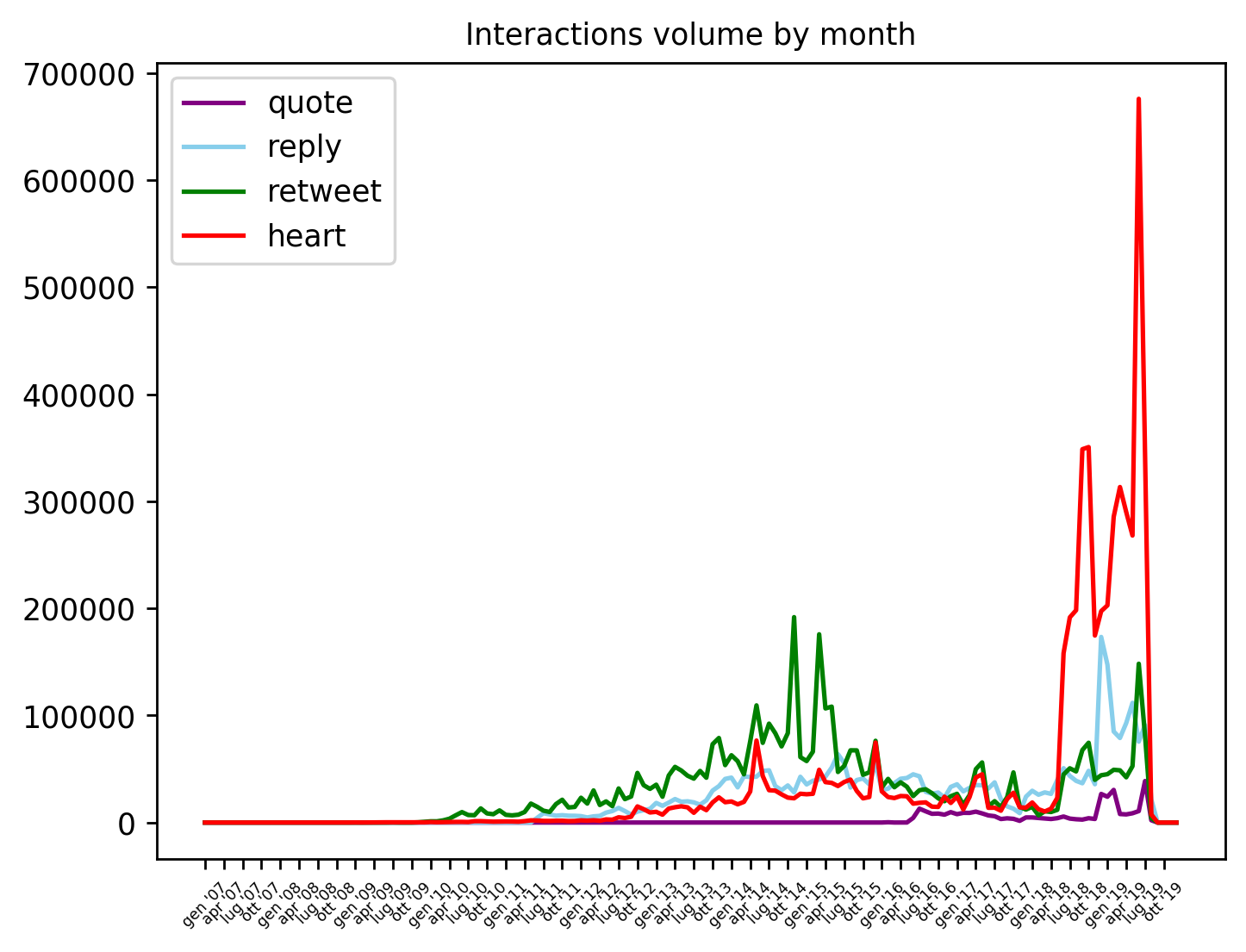
I really cannot explain the spike of hearts during 2019. My best guess is that some tweets became viral without a particular reason, like porn contents. I wrote a thread on Twitter some time ago.
Chinese Tweets
Now I will focus on tweets written in Chinese, that can only be read by Chinese-speaking people. This time I used the command:
python3 tweets_analysis.py --dirpath alldata --tlang zh -csv -txt -v
So I can see only data about Chinese (zh) tweets.
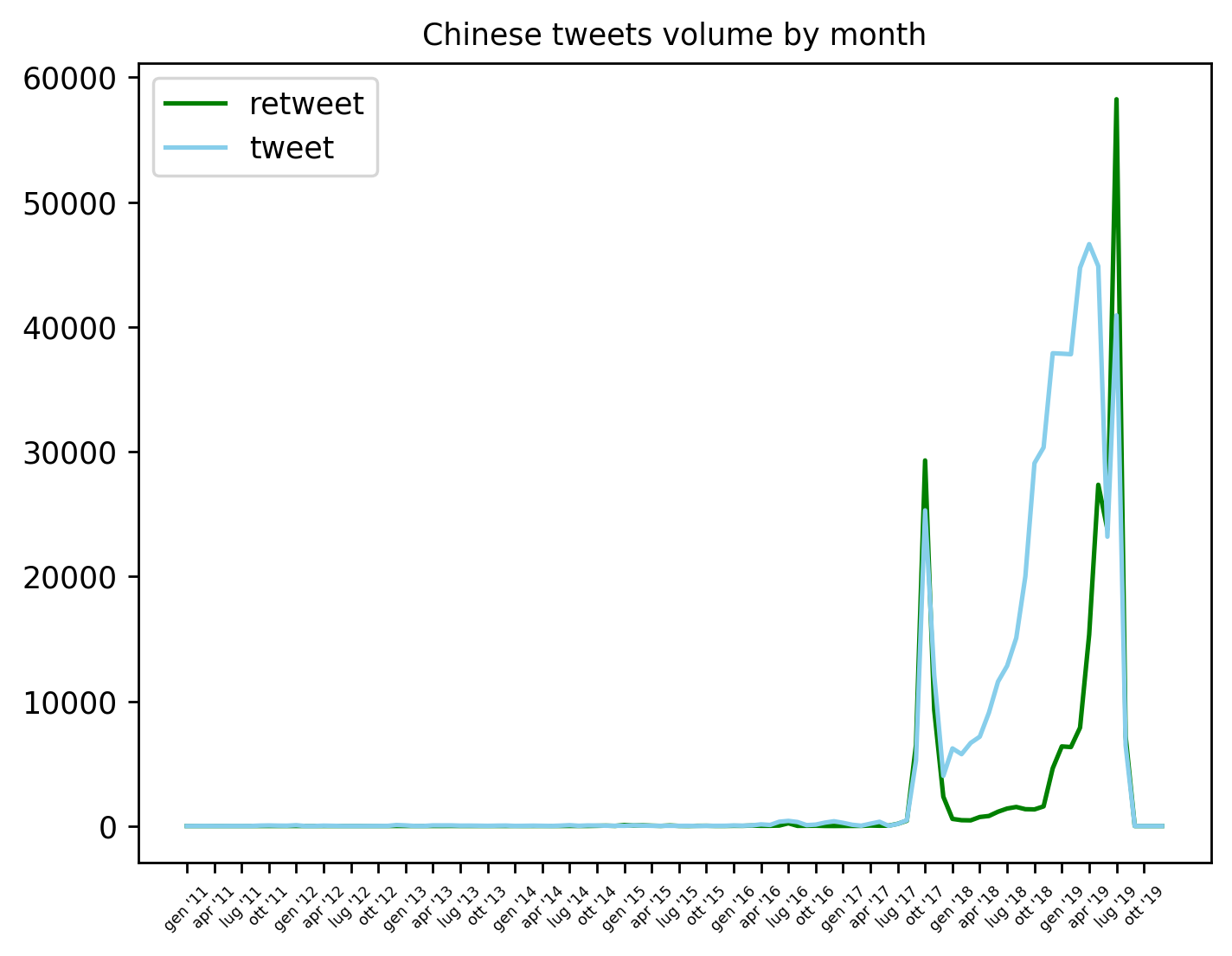
The Chinese tweets are less than a million, not so many if compared with English tweets (~ 2,5 millions) or Indonesian tweets (~ 4 milions). The volume growth is interesting: there is a spike in October 2017 and there is a fast growth between October 2018 and July 2019, with two strong spikes in April and July. The ASPI’s study shows how, in the dataset #1 and #2, there are conspiracy tweets targeting anti-government opponents, which may be a first attempt to influence the online opinion. Also, in the dataset #3 there is a high volume, during 2019, that coincides with Hong Kong protests’ period. The most frequent hashtag is #香港, which means “Hong Kong”, while the second one is #HongKong, used in 31.677 tweets. 29.866 of these are classified as Chinese (zh). The third most popular hashtag is #HK. Almost every tweet about Hong Kong is written in Chinese, they are probably targeting Chinese people, especially who lives overseas, because Twitter is blocked in China. Another interesting fact regards the retweeted accounts, I haven’t checked every single one but it seems that they have all been suspended by Twitter, even if they were only retweeted once and they aren’t present in the dataset.
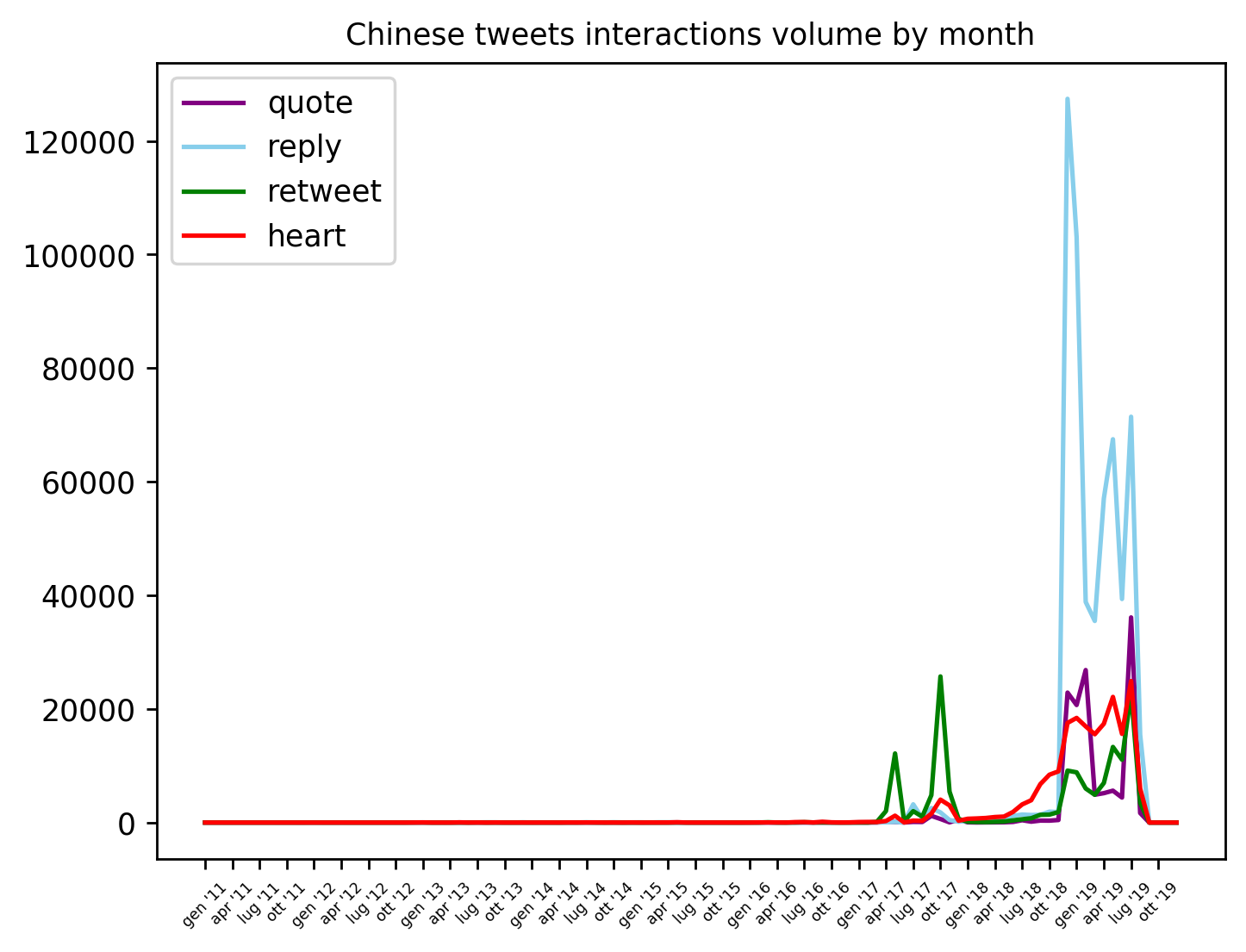
These tweets have generated a peculiar graph of interactions: there is a huge spike in the replies, which is uncommon, and I cannot tell whether the accounts who replied to Chinese bots are humans, bots or both. However, the propaganda has not generated many retweets or hearts, so they haven’t become viral like Internet Research Agency contents. Unfortunately I don’t understand Chinese, so I can’t see the tweets’ contents. The two last graphs show the coordinated behavior of these account:
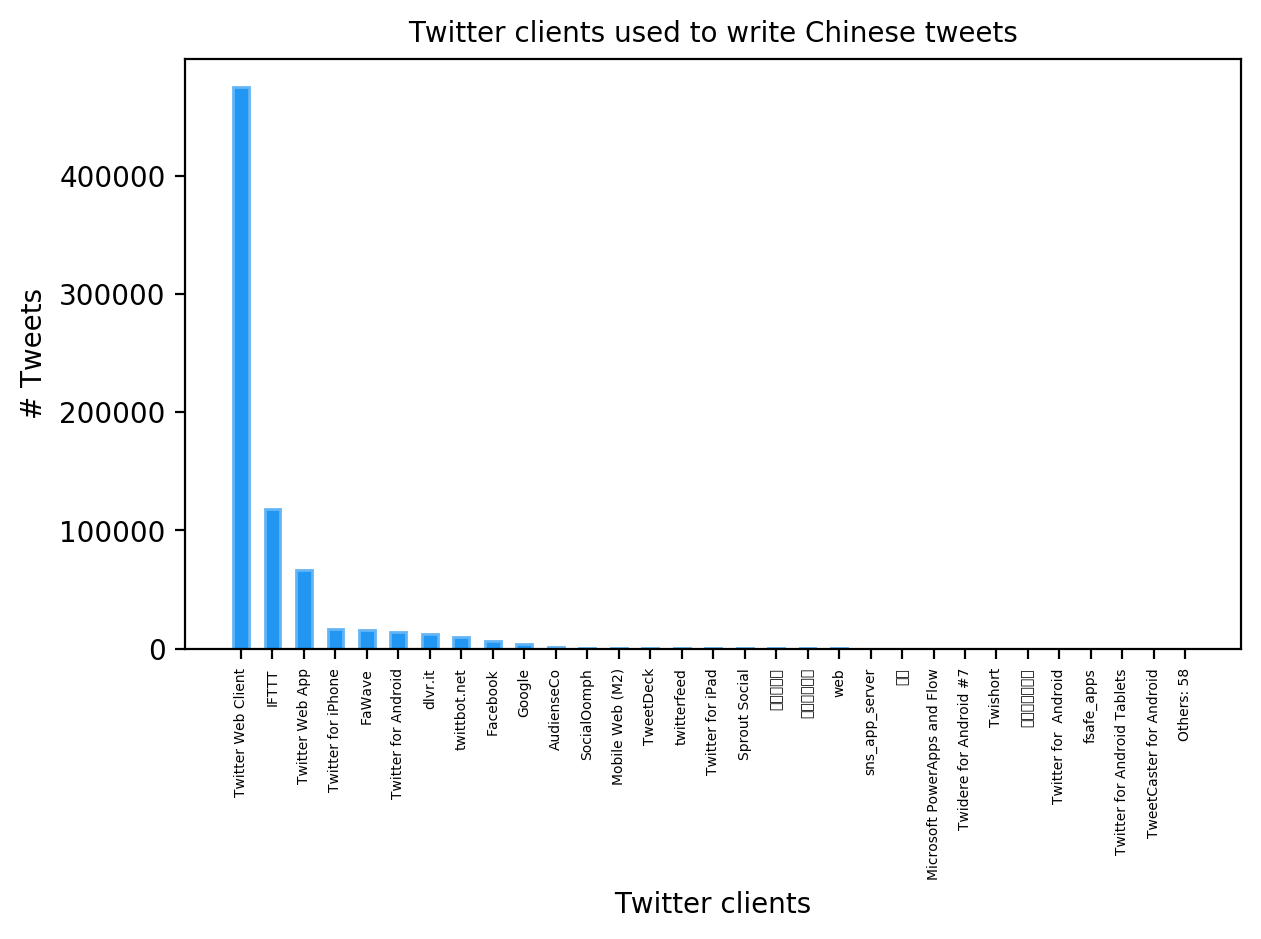
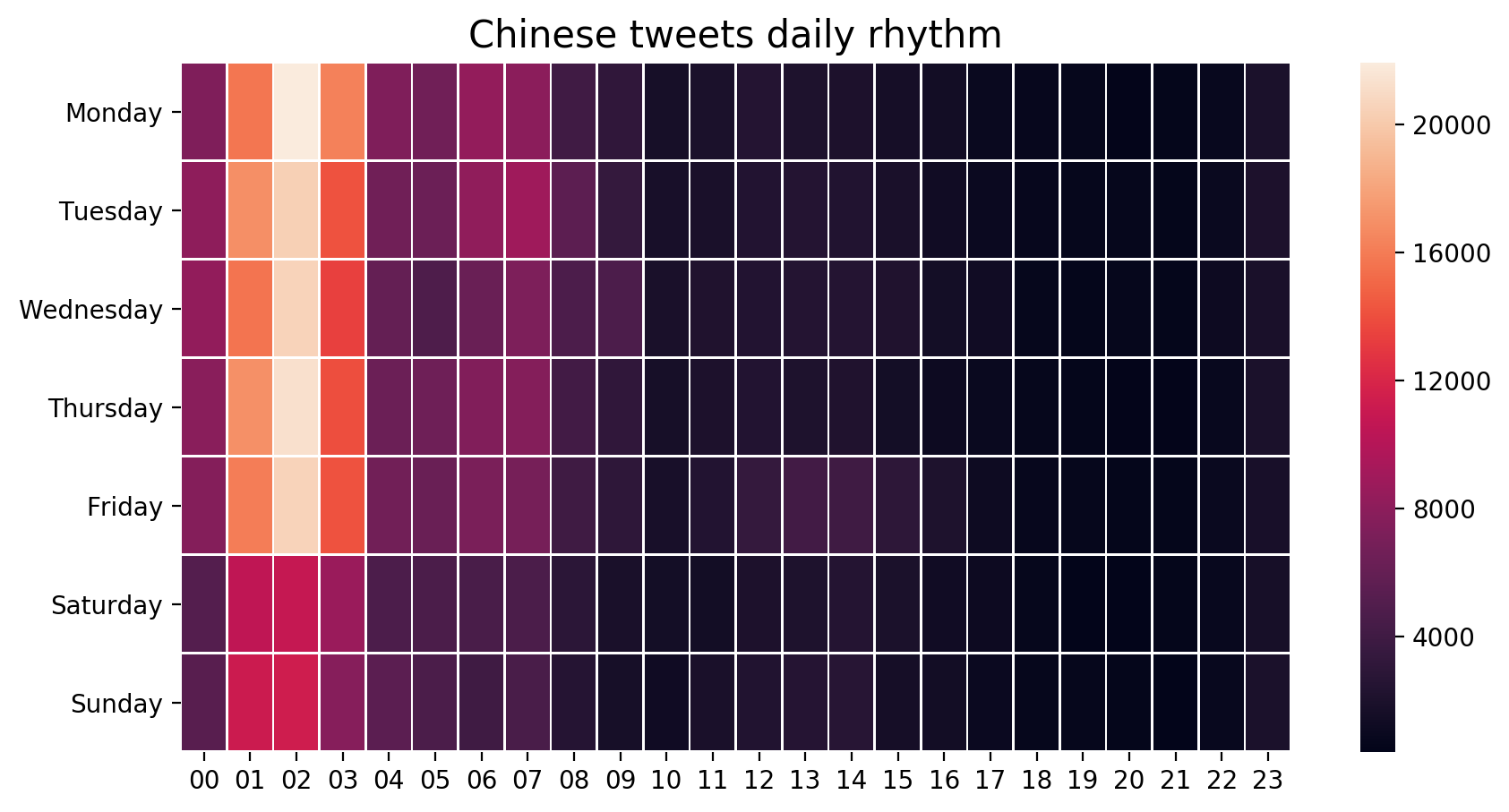
The most used clients are Twitter Web Client (browser) and FTTT. They are easily “hackable” and are often used to automate the accounts. This inauthentic behavior seems to be confirmed by the daily rhythm: most of Chinese tweets are mainly published between 9:00 a.m. and 11:00 a.m. (local time) during the work week, the same pattern can be also noticed during the weekend, but there is a lower volume. In my opinion this pattern is a weak and failed attempt by the malicious agents to simulate a natural and human behavior.
Conclusion
I have written tweet_analysis.py to help people who want to read and understand the datasets shared by Twitter. This script creates graphs and shows some information in a “human-friendly” way. My main difficult with these datasets has been the language: I don’t know Chinese, so I cannot read tweets and Google Translate doesn’t work very well with Chinese. However, these graphs raise many interesting points: the Internet Research Agency propaganda was based on microtargeting and well planned, there were many groups of trolls with different features to reach different people, while Chinese propaganda is “young”, maybe it has been commissioned to private companies, I cannot see a well-planned strategy like the Russian one. These data are important because they acknowledge that China wants to be a player in this game, also outside its borders - it doesn’t come as a surprise - and they also confirm that Twitter is still important to share information, reach the journalists quickly and lead protests. I want to thank Niccolò Battolla who is helping me to improve my script, I hope I will add some more features soon. You can find the graphs and data of this post on my Dropbox.